
https://openreview.net/forum?id=CMzF2aOfqp
Introduction
DNNは強力だが学習力が高くてNoisy Labelの場合そのNoisyな部分まで過学習してしまう。これへの対策手法の1つはEarly Stoppingである。
だが、これはvalidation Datasetのaccuracyなどで判断するが、学習に使えるデータが減るということでもあるのでモデルの全体の性能を制限してしまう。
この論文ではValidation Dataset不要なEarly Stoppingを提案する。Training Lossについて一旦下がり、Noiseを学び始めたら上がり、そして過学習してまた下がっていくという過程があると経験的にわかったので、これをうまく検出する手法を開発した。
Prediction Changesという指標を導入して、2つの連続するEpochの間で予測を変更したサンプルの数について数えたら、ちょうど合致してそうだとわかった。
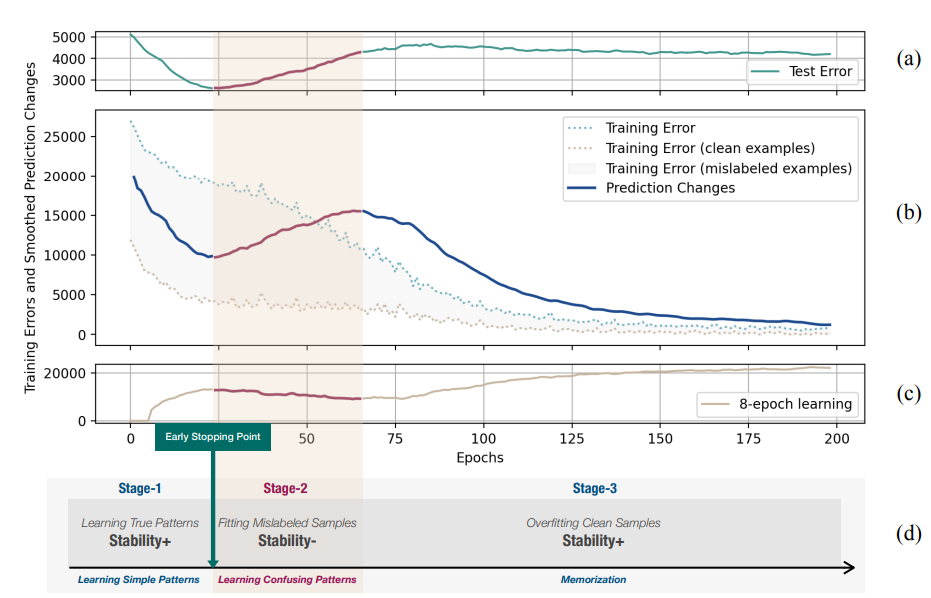
下図のaはtest data’s error。bはPrediction Changes。Stages2での誤ったラベルの学習はTest Dataの正解率を下げるだけではなくせっかく学んだTrain Dataの正解率も下がる。
Related Works
- 誤ったラベルのデータを学習すると、今まで学んできた内容すら忘れてしまう=Forgetting Eventという問題がある。
- PUでのEarly StoppingでTrend Scoreを使ったものがある。
- 最初は簡単なものを覚え、そこからノイズにような難しいものを覚えるMemorization Effectの話がある。
- Curriculum学習を使った、データごとのHardnessを評価するものもある。簡単な例から学んでもらう感じ?
Early Stoppingの手法提案
過学習
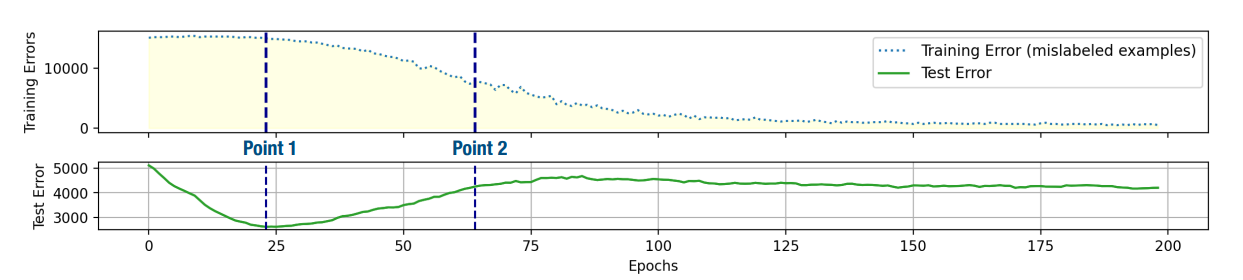
このように過学習は起こる。
安定性の評価
各サンプルについて、直近kエポックすべてで正しく分類している=安定して正しく予測していると扱う。これはk-epoch learningという。
変動性の評価
各サンプルについて、毎エポックの間に予測を変更した数=Prediction Changesを変動性の評価指標とする。
Mislabeled Samplesを学習するとTrainもTestも性能下がる
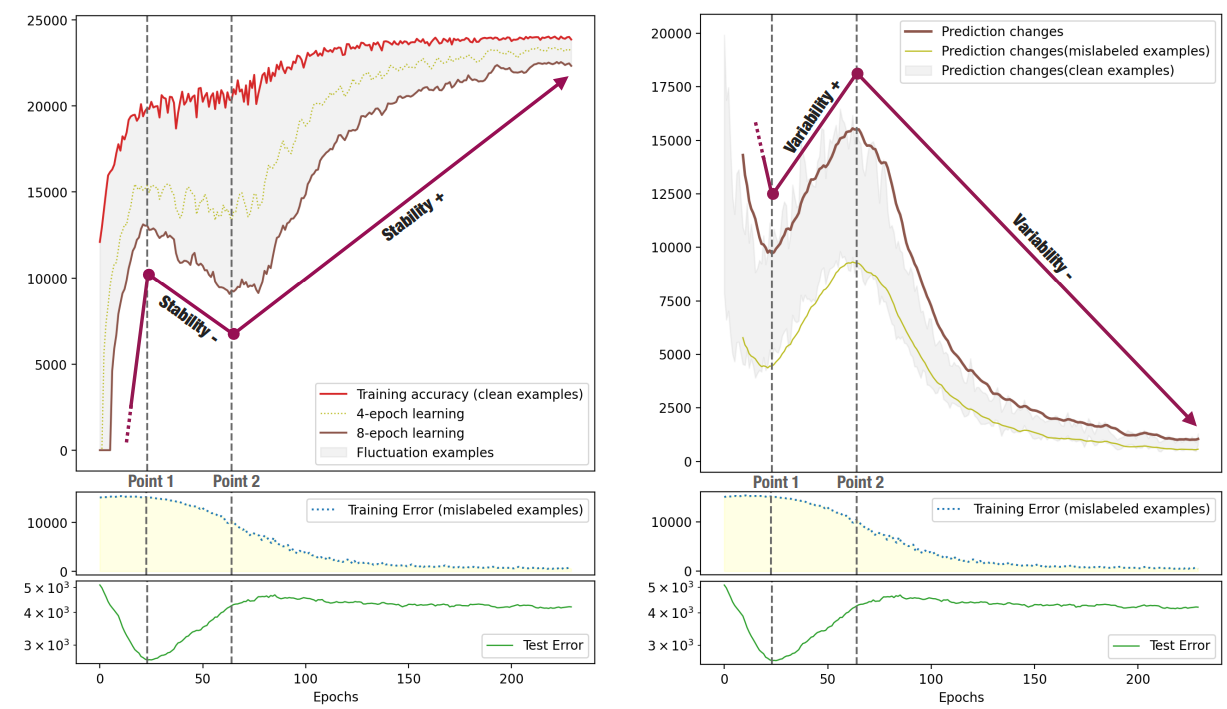
- 左図はk epoch learning(安定性指標)の図。安定性は明確に3つの状態で増減増になり。test errorのturning pointと近いとわかる。
- 右図はPrediction Changesの図で、明確に減増減でこれもtest errorと対応しているとわかる。
提案手法
k epoch learningではなくPrediction Changesを指標として使う。
個々の波動はそれなりにあるので、直近個のPrediction Changesの移動平均を指標として使う。そして、この指標が迎えた最初の最小値がEarly Stoppingの点。
手法の欠点
ラベルノイズが非常に少ない、ない場合は明確なPrediction Changesが見えてこないので逆にきつい。
また、現代のDNNはover parametorizedなどで、Overfittingしてようがうれしいことだってある。
Experiments
- CIFAR10, CIFAR100, CIFARMは人工的にノイズを付与。
- 対称ノイズ、40%の間違え率を使う。
- Clothing1M, WebVision, Food101は最初からノイズある。
- NEWSとかも使ったらしい。